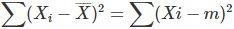우리는 앞서 변산성에 대해 배우면서 집중경향에 대해서도 살펴봤지. 이제는 집중경향에 대해 자세하게 알아볼거야. 집중경향(central tendency)은 말 그대로 '얼마나 중앙에 집중되어 있는지.'를 뜻 해. 바꿔말하면 분포의 중심을 대표하는 값이야. 그리고 중심경향의 지표로는 평균이나 중앙값 혹은 최빈값이 될 수 있어. 상황에 따라 달라질 수 있기 때문이야.
부모들은 자신의 아이가 첫 걸음마를 언제 떼는지 알고 싶어해. 그토록 기다리던 내 아이의 첫 걸음마를 보고싶기도 하고, 또 내 아이가 다른 아이들보다 걸음마를 빠르게 떼는지, 늦게 떼는지 알고 싶기 때문이지. 그럼 아이들은 언제 걸음마를 뗄까?
답은 대충 12개월이라고 할 수 있어. 왜 '대충'이라고 했게? 사실 이 물음에 대한 대답은 쉽지가 않아.
일단 우리가 배운것을 적용해 볼게. 아이들이 언제 걸음마를 떼는지 알기 위해서 전세계 모든 유아들을 대상으로 관찰할 수 없잖아? 그치? 현실적으로 불가능하지. 그래서 우리는 표본을 선정해서 유아들이 언제 첫 걸음마를 떼는지 관찰해야 돼. 빈도분포를 알 수 있겠지? 도표도 그릴 수 있겠구 말야. 그렇게해서 표본의 유아들이 언제 첫 걸음마를 뗴는지 알아냈다면, 분포를 대표하는 중심경향에 대해서도 생각해 봐야 돼. 중심경향의 지표로 어떤 것을 쓰면 좋을지 말야.
우리가 흔히 쓰는 '평균(mean)'으로 정하면 되지 않을까? 안돼. 앞서 마이클 조던의 초봉 사례를 통해 평균이 집단을 대표하지 못 할 수도 있다는 것을 배웠잖아.
그럼 절반의 아이들이 첫 걸음마를 떼고 나머지 절반의 아이들은 아직 걸음마를 떼지 못하고 있는 바로 그 중앙을 나타내는 '중앙값(median)'으로 정하면 되지 않을까? 아니면 걸음마를 떼는 것이 제일 많이 관찰되는, 즉 빈도가 가장 높은 '최빈값(mode)'으로 정하면 될까? 으악!
이 세가지 지표들이 같을수도 있고 다를 수도 있어. 같으면 좋겠지만 다르다면 어떡하지? 만약 걸음마를 떼는 나이의 평균은 11.7개월이고 중앙값은 12.2개월이라면? 2주 정도야 우리에게는 별 것 아닌 것 처럼 보일 수 있어도 아이를 기르는 부모로서는 긴 시간으로 생각될 수 있어.
그럼 이런 궁금증이 생길거야. '왜 이 세가지 지표들의 값은 같지 않은가?', '그렇다면 무엇이 가장 중심경향의 지표로서 알맞은가?' 그치? 이러한 궁금증의 원인은 부모로서의 당연한 생각이야. 만약 내 아이가 10개월만에 걸음마를 뗐다면 다른 아이들보다 발달이 빠른 것이라고 할 수 있는지, 혹은 만약 내 아이가 14개월만에 걸음마를 뗐다면 내 아이가 다른 아이들보다 발달이 느린 것인지 알고 싶기 때문이지. 사실 부모라면 누구나 내 아이가 발달이 느린 것을 원치 않겠지만 현실은 절반의 아이들은 중앙값보다 발달이 느릴 수 밖에 없어.
이 물음에 답하기 위해서는 변산성에 대해 이해해야 돼. 변산성은 흩어진 정도라고 했지? 기억해야 돼.
만약 유아들은 관찰해서 가장 빠르게 걸음마를 떼는 아이가 8개월이었고, 가장 느리게 걸음마를 떼는 아이가 20개월이었다면 10개월만에 걸음마를 떼는 것이 정말 발달이 빠르다고 할 수 있을까? 혹은 14개월은 정말 느리다고 할 수 있을까?
이 물음에 답하고자 통계학자들은 '분산(variance) 혹은 변량'과 '표준편차('standard deviation)'이라는 변산성의 지표를 만들었어. 드디어 나왔네! 분산과 표준편차. 이번 시간에는 집중경향의 지표들을 배워보고 분산과 표준편차에 대한 개념을 같이 배울까..? 다음 장에서 배울까..? 분량 봐서 결정해야겠다.
-
먼저 우리에게 익숙한 평균에 대해 배워볼게.
그냥 평균(average)라고 하면 산술평균(arithmetic mean)을 의미한다고 했지? 그리고 평균은
1. Xi와 m의 차이의 합은 Xi의 합과 m의 합의 차이와 같음. 2. m은 상수이기 때문에 상수를 N번 더한 것과 상수에 N을 곱한 것은 같음. 3. 평균을 뜻 하는 m을 평균의 계산식 ∑Xi/N으로 치환. 4. N(∑Xi/N)에서 N을 약분하고 나면 ∑Xi가 됨.
어때? 증명도 되었지?
이제 우리는 어떤 점수치들이든 편차들의 합이 0이라는 것을 깨달았어. 하지만 0을 가지고 뭘 하겠다는 걸까? 0은 별로 쓸모가 없어. 더구나 점수치들은 다 다른데 무조건 0이라면 무슨 의미가 있겠어 그치?
그래서 통계학자들은 편차를 그냥 합하지 않고 제곱해서 합하기로 했어. 그래야만 의미있는 수치들을 얻을 수 있거든! 이번에는 편차들의 제곱을 합해볼까?
편차 제곱들의 합
:점수치들(Xi)
Xi-m (평균에서의 편차)
(Xi-m)²
3
-2
(-2)² = 4
7
2
2² = 4
5
0
0² = 0
1
-4
(-4)² = 16
9
4
4² = 16
∑Xi (점수치들의 총합) = 25
∑(Xi-m)² = 편차의 제곱들을 다 더한 것 = 4+4+0+16+16 = 40
N (점수치들의 개수) = 5
m (평균) = ∑Xi / N = 25 / 5 = 5
편차들의 합은 0이지만 편차 제곱들의 합은 완전히 다른 숫자가 나오지! 편차 제곱들의 합은 보통 0이 되지 않아.
<편차의 첫 번째 성질>
∑Xi-m은 0이지만,
∑(Xi-m)²은 보통 0이 되지 않아.
물론 모든 점수치와 평균이 같다면 편차 제곱들의 합도 0이 될 수 있을거야. 하지만 그런 경우는 거의 없으니까 '보통 0이 되지 않는다.'라고 표현했어.
그럼 이 편차 제곱들의 합을 가지고 뭘 할 수 있을까?
여기서 편차의 두 번째 성질을 알 수 있어. 두 번째 성질을 알려주기 전에!
만약 평균 말고 무작위로 숫자 하나를 정해놓고 각 점수치들로부터의 편차 제곱들의 합을 구해보면 어떻게 될까? 예를 들어 위의 점수치들의 평균은 5이기 때문에 각 점수치들에서 5와의 차이를 구하고 제곱을 한 다음에 다 더해줬잖아. 근데 이번에는 5가 아닌 다른 숫자로부터의 편차를 구한 다음 제곱의 합을 구해보는거야. 무작위 숫자는 내 맘대로 7과 2로 정해볼게.
:점수치들(Xi)
내 맘 대로 정한 숫자 7에서의 편차
내 맘 대로 정한 숫자 2에서의 편차
(Xi-7)²
(Xi-2)²
3
-4
1
(-4)² = 16
1² = 1
7
0
5
0² = 0
5² = 25
5
-2
3
(-2)² = 4
3² = 9
1
-6
-1
(-6)² = 36
(-1)² = 1
9
2
7
2² = 4
7² = 49
∑(Xi-7)² = 16+0+4+36+4 = 60
∑(Xi-2)² = 1+25+9+1+49 = 85
내 맘대로 정한 숫자 7에서의 편차 제곱들의 합은 60이 나왔어. 그리고 2에서의 편차는 85가 나왔지! 둘 다 40보다는 큰 숫자가 나왔어. 우연일까? 아니야. 그 어떤 숫자라도 평균에서의 편차 제곱들의 합 보다는 큰 숫자가 나올 수 밖에 없어. 이걸 '최소제곱의미(least square sense)'라고 해. 이 최소제곱의미를 통해 '최소제곱법(least square method)'에 대해 알 수 있어. 최소제곱법에 대해서는 나중에 다시 알아보기로 하고 최소제곱의미에 대한 증명을 볼까?