-
03-3 변산성의 지표 1 : 분산과 자유도데이터 분석/스프레드시트로 배우는 데이터 분석을 위한 통계학 2021. 11. 25. 11:18
드디어 분산과 표준편차가 등장했구나~!~!
사실 이전까지의 글들은 분산과 표준편차에 대해 설명하기 위한 빌드업이었지. 빌드업치곤 너무 긴거 아니냐고? 그만큼 분산과 표준편차가 중요하니까! 빌드업도 길게 했던거지!
분산과 표준편차에 대해 알아보기 전에 변산성에 대한 정의를 다시 떠올려볼까?
변산성은 '점수들이 흩어진 정도', '점수들이 평균에서 떨어진 정도', '점수들이 서로 다른 정도'와 같은 의미를 갖고 있었어. 기억나지? 예를 들어 A집단의 점수들이 '60, 70, 80'이고 B집단의 점수들이 '50, 70, 90'이라고 가정해 볼게. 두 집단의 평균은 70으로 같겠지만 B집단이 A집단보다 변산성이 더 크지! B집단의 점수들이 평균으로부터 더 많이 떨어져있기 때문이야.
그럼 변산성에 대한 개념을 알았으니 변산성을 수치화 할 순 없을까? 있지!
일단 점수들의 범위(range)를 통해 변산성을 측정할 수 있을거야. 점수들의 범위가 얼마나 되는지 알아보려는거지. 범위를 알아보려면 점수들 중에서 가장 큰 값과 가장 작은 값의 차이를 구하면 돼. 만약 C집단의 점수들이 '10, 20, 50, 80, 90'이라면 C집단의 범위는 제일 큰 점수인 90에서 제일 작은 점수인 10을 뺀 값, 즉 80이 되는거야.
범위는 한 분포의 변산성을 반영하고 있어. 하지만 모든 점수들이 다 범위에 민감한것은 아니야. 제일 작은 점수와 제일 큰 점수만이 범위에 영향을 끼치기 때문이지. 예를들어 D집단의 점수들이 '10, 40, 50, 60, 90'이라면 D집단과 C집단은 범위가 같겠지?
C집단 X1 X2 X3 X4 X5 10 20 50 80 90 D집단 X1 X2 X3 X4 X5 10 40 50 60 90 두 집단 모두 제일 큰 점수가 90이고 제일 작은 점수가 10이니까. 또, 두 집단은 범위만 같은것이 아니라 평균도 같아. 둘 다 50이지. 그렇다면 평균과 범위가 같으니 변산성도 같을까? 아냐! 도표로 살펴볼까?

C집단 
D집단 도표로 살펴보니 C집단의 점수들이 D집단에 비해 평균에서 더 멀리 떨어져있는 것을 쉽게 알 수 있어. 범위만으로는 변산성을 나타낼 수 없다는 뜻이지. 하기사 이렇게 쉽게 구할 수 있는 지표가 어떻게 변산성을 대표할 수 있겠어~
그럼 다른 지표는 없을까? 그게바로! 분산(variance)이지! 분산은 s²과 같이 나타내기도 해.
분산은 변산성을 반영하면서도 범위가 가지고 있는 한계점이 없어. 먼저 분산을 어떻게 구할 수 있는지 살펴보면서 분산에 대해 살펴볼까?
분산 S²은
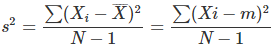
분산 variance 와 같이 구할 수 있어.
딱 보면 어려운 수식으로 보이지만 잘 살펴보면 우리가 이미 배웠던 내용이라는 것을 알 수 있지!
Xi는 점수치, m(엑스바)은 평균이라는거 기억하고 있지? N은 점수들의 전체 개수를 뜻하고 말야. ∑(Xi-m)²은 편차 제곱들의 합이라는 것도 기억하고 있지? 그럴리 없겠지만 혹시라도 생각이 안나는 친구들은
https://kimhaksung.tistory.com/entry/simtong03-1
03-1 중심경향의 지표 : 평균
우리는 앞서 변산성에 대해 배우면서 집중경향에 대해서도 살펴봤지. 이제는 집중경향에 대해 자세하게 알아볼거야. 집중경향(central tendency)은 말 그대로 '얼마나 중앙에 집중되어 있는지.'를
kimhaksung.tistory.com
요 포스트를 복습하고 오면 돼! 그리고 편차 제곱들의 합, 즉 제곱합(혹은 자승합, 자승화)은 영어로 Sum of Squares, 줄여서 SS라고도 표기하니까 잊지마!

제곱합을 나타내는 SS와 분산을 나타내는 s²는 비슷하게 생겼지만 다르다는 것도 유념해야 돼! 제곱합을 SS로 나타낸다는 것을 배웠으니 분산 또한 더 쉽게 나타낼 수 있게 되었어!

그치? 앞으로 SS가 나오면 '아! 제곱합이구나!'라고 알아들어야 돼. 그리고 SS를 N-1로 나눈 것이 보이면 '아! 분산 S²'이구나! 라고도 알아들어야 돼. 꼭!
이제 분산에 대해 다시 살펴보면, 분산은 결국
평균과 점수들의 차이, 즉 편차를 제곱한 것들의 합의 평균
을 나타내. 평균에 대해 떠올려보면 점수들을 다 더해서 점수들의 개수로 나눈 거잖아?
분산도 편차 제곱들을 다 더해서 점수들의 개수로 나눈거니까 평균의 개념과 같은거지!
어? 그런데 평균을 구하려면 전체 개수를 뜻하는 N으로 나눠야 하는데 N에서 1을 뺀 N-1로 나누니까 평균과 조금 다른거 아닌가? 라고 생각이 들 수 있어.
맞아! 그런 생각이 들었다면 당신은 공부를 열심히 했으므로 칭찬을 받아야 합니다. 참 잘했어요!
그럼 왜 평균을 구하는데 N이 아니라 N-1로 나눈 것일까? 라는 물음에 대해 생각해 볼까?
사실 모집단의 분산을 구하려고 한다면 N-1로 나누는것이 아니라 N으로 나누는 것이 맞아. 우리가 알고있는 평균의 개념대로 말야. 하지만 모집단으로부터의 표본집단의 분산을 구하려고 한다면 N-1로 나누는 것이지!
예를들어 가톨릭대학교 심리학과 1학년 학생들이 모두 200명이라고 가정해 볼게. 200명은 심리학과 1학년 학생들의 모집단이 되겠지? 이때 심리학과 1학년 학생들의 점수에 대한 분산을 구하기 위해서는 200으로 나누는것이 맞아. 하지만 모집단에서 30명을 추출해서 표본집단을 만들고 분산을 구한다면 30이 아니라 29로 나눠야 해. 왜?
통계치가 상응하는 모수치에 대한 더 좋은 추정치가 되도록 하기 위해서야.
라고 하면 말이 어렵지.
다시 편차에 대한 질문으로 돌아가 볼게. 우리가 편차를 알아보려한 이유는 뭐였지? '내 점수가 평균에서 얼마나 떨어져 있는가?'라는 물음에 답하기 위해서였지. 그런데 이걸 왜 알려고 하는걸까? 더 원론적으로 물어보면 우리는 왜 통계를 배우는 것일까?
왜 통계를 배우는 것일까?
학교에서 가르치니까? 점수를 잘 받으려고?
대한민국의 인구는 약 5,180만 명 정도라고 해. 만약 여러분이 대한민국 모든 인구의 신장(키)에 대해 알고 싶다면 어떻게 해야될까? 5,180만 명 모두를 찾아 다니면서 키를 재고 기록하면 될까? 할 수만 있다면 가장 좋은 방법이겠으나..
하지만!!! 그렇게하면!!! 힘들고!!! 돈도 많이 들고!!! 시간도 많이 들고!!!
그치? 그래서 우리는 쉽고 간편하면서 돈도 적게 들고 시간도 적게 쓸 수 있는 방법을 생각해냈어. 그게 바로 통계학이지. 꼭 5,180만 명 모두 모두를 조사할 필요는 없어. 통계학은 5,180만 명 중에서 대충 수십 명을 뽑아서 평균을 내보면 전체 인구의 평균과 비슷하지 않겠느냐는 생각으로 부터 출발했기 때문이지.
그럼 대체 5,180만 명 중에서 몇 명이나 뽑아야 될까? 십분의 일, 518만 명만 뽑을까? 아님 51만 명? 땡!
딱 정해진 숫자는 없어. 숫자가 많을 수록 정확도가 높아지겠지만 우리는 최소한의 노력으로 최대한의 결과를 얻어내고자 하는 거잖아. 따라서 높은 정밀도가 요구되지 않는다면 수십 명도 괜찮아. 우리가 공부하고 있는 심리통계학과 같은 사회과학 분야에서는 표본을 2~30정도로 정해 놓았어. 굉장히 적어보이지? 하지만 어쩌겠어! 시간과 비용을 절약해야 되는데!
모집단(전체)에서 2~30명을 뽑아낸 집단을 표본집단(일부)라고 하지? 표본을 추출했다고 해. 표본을 추출하는 방법은 여러가지가 있겠지만 무작위로 표본을 추출하는 것이 좋을거야. 그래야 공정하니까.
자, 이제 통계학을 통해 전체를 다루기 어렵기 때문에 전체 중 일부만을 다루어 전체에 대해 알아볼 수 있도록 한다는 것을 이해하겠지? 그럼 다시 분산에 대한 이야기로 돌아가 볼게.
무한 장의 숫자 카드들이 있다고 가정해 볼게. 카드가 모두 몇 장인지는 알 수 없어. 무수히 많지. 단, 이 무한 장의 숫자 카드들의 평균은 50으로 정해져 있다고 할게. 왜? 분산을 구하려면 편차를 알아야 하는데 편차는 평균과 점수의 차이잖아. 그러니 평균을 딱 정해놓자는 거지. 알았지?
암튼 이 카드들 중에서 딱 열 장만 무작위로 뽑을거야.
첫 번째로 뽑은 카드는 3이었지. 두 번째 카드의 숫자는 -26이었어. 세 번째 카드는 13이었지.
이런 식으로 아홉 번째 카드까지 뽑았다고 가정해 볼게. 아홉 장의 카드를 다 뽑은 다음 숫자들을 모두 다 더해보았더니! 아홉 장의 숫자 카드들의 합은 493이 나왔어.
이제 마지막 열 번째 카드를 뽑아야 돼. 과연 마지막 카드를 무작위로 뽑는것이 가능할까?
안돼!
무한 장의 숫자 카드들의 평균이 50으로 정해져 있었잖아. 평균이 50이 되려면 마지막 열 번째 카드는 7이 적힌 카드여야만 해. 그래야 열 장의 카드들의 합이 500이 나오면서 평균이 50이 되니까.
바꿔말하면, 아홉 번 째 카드를 뽑는 순간 열 번째 카드의 숫자는 정해져 버리는거야. 자유를 잃어버린 것이지.
모집단에서 무작위로 추출한 표본들은 모집단과 평균이나 변산성이 같아야만 할거야. 그치? 그래야만 통계학을 배우는 의미가 있잖아.
다른 예를 들어볼까?
몸무게가 모두 같은 열 명의 아이들이 있다고 가정해 볼게. 이 아이들이 무한한 길이를 가지고 있는 시소에 앉기로 했어. 단, 어떻게 앉든지 간에 모든 아이들이 다 시소에 앉았을 때 시소가 평행을 이루도록 할거야. 어느 한 쪽으로도 기울어지지 않게.
첫 번째 아이가 아무데나 앉았어. 자기가 앉고 싶은 곳에 말야. 두 번째 아이도 아무데나 앉았지. 세 번째 아이도 앉고.. 여덟 번째 아이까지 모두 앉았어. 그리고 드디어 아홉 번째 아이가 앉았는데, 글쎄! 시소가 오른쪽으로 기울어진거야!
그럼 열 번째 아이는 자기가 앉고 싶은 자리에 앉을 수 있을까? 안돼! 시소를 평행하게 만들어야 한단 말야. 아홉 번째 아이가 앉았을 때 오른쪽으로 기울어졌으니까 열 번째 아이는 왼쪽 어딘가, 시소를 평행하게 만드는 위치에 앉을 수 밖에 없어. 열 번째 아이가 앉아야 될 자리는 정해져 있는거지. 자유가 없어.
제일의아해가아무곳에나앉겠다고고그리오.
제이의아해도아무곳에나앉겠다고고그리오.
제삼의아해도아무곳에나앉겠다고고그리오.
제사의아해도아무곳에나앉겠다고고그리오.
제오의아해도아무곳에나앉겠다고고그리오.
제육의아해도아무곳에나앉겠다고고그리오.
제칠의아해도아무곳에나앉겠다고고그리오.
제팔의아해도아무곳에나앉겠다고고그리오.
제구의아해도아무곳에나앉겠다고고그리오.
제십의아해는아무곳에나앉을수가업소.(다른사정은업는것이차라리나앗소)
- 자유도 시제1호
이게 자유도(degree of freedom, df)의 개념이야.
그리고 분산을 구하기 위한 공식이 SS를 N으로 나누는 것이 아니라 N-1로 나누는 이유이기도 하지.

분산은 자유에요 어? 그럼 모집단이 진짜 말도 안되게 크지 않아서 한 번 덤벼볼만 할 만큼 적당히 크다면, 모집단의 분산을 구할 땐 SS에서 N으로 나눠도 되나? 라고 생각할 수 있으면 자네는 짱일세.
맞아. 만약 표본집단의 분산이 아니라 모집단의 분산을 구하려 한다면 N으로 나눠도 돼! 모집단에 대한 분산은 다음에 다시 설명할게.
다음으로는 표준편차(standard deviation)가 무엇인지 알아볼까?
'데이터 분석 > 스프레드시트로 배우는 데이터 분석을 위한 통계학' 카테고리의 다른 글
03-5 모집단과 표본집단 : 모수치와 통계치 (0) 2021.12.02 03-4 변산성의 지표 2 : 분산과 표준편차 (0) 2021.11.25 03-2 중심경향의 지표 : 중앙값과 최빈값 (0) 2021.11.23 03-1 중심경향의 지표 : 평균 (0) 2021.11.18 02-1 도표와 변산성 : 분포들은 어떻게 다른가? (0) 2021.11.17