-
03-4 변산성의 지표 2 : 분산과 표준편차데이터 분석/스프레드시트로 배우는 데이터 분석을 위한 통계학 2021. 11. 25. 15:12
이제 표준편차(standard deviation)에 대해서 배울건데, 표준편차를 배우기에 앞서 분산과 편차에 대해 다시 생각해 볼 필요가 있어. 편차 제곱의 합이 분산이었고, 편차는 점수가 평균으로부터 떨어진 정도였지? 제곱을 한 이유는 편차들을 다 더하면 0이 되어버리기 때문이었고. 기억하지?
그리고 초등학교 때 배웠던 것을 떠올려보면 제곱을 통해 정사각형의 면적을 구할 수 있잖아? 편차 제곱도 마찬가지야. 편차를 제곱 하면 편차의 면적을 구할 수 있지. 그리고 그것들을 다 더해서 나눠주면 편차 면적들의 평균을 구할 수 있어. 결국 분산은 편차 면적들의 평균이 되는거야.
그럼 편차의 면적을 다시 편차로 되돌려놓으려면 어떻게 하면 될까?
간단해! 루트를 씌우면 되지!
분산, 즉 편차 면적들의 평균에 루트를 씌우면 편차들의 평균이 될거야. 하지만 분산을 통해 구한 편차들의 평균은 0이 아니야. 의미있는 값을 가지고 있지. 이게 바로 표준편차야.
표준편차는 '분산의 제곱근', 혹은 '분산에 루트를 씌운 것'이라고 할 수 있어. 그래서 표준편차는 s로 표기해. 분산을 s²으로 표기하기 때문이야.

분산의 제곱근 그럼 표준편차도 분산을 구했던 것 처럼 수식으로 나타낼 수 있겠지?

표준편차 standard deviation 이것이 표준편차의 정의야. 분산에 루트만 씌워주면 되니까 어렵지 않지?
마지막으로 정리하면,
- 편차 : Xi-m : 점수에서 평균까지의 차이
- 편차의 제곱 : (Xi-m)² : 점수에서 평균까지의 면적
- 편차 제곱들의 합 : 제곱합 : SS : ∑(Xi-m)² : 편차 면적들을 다 더한 것
- 편차 제곱들의 평균 : 분산 : s² : ∑SS/(N-1) : 편차 면적들의 평균 (자유도 개념)
- 편차 제곱들의 평균의 제곱근 : 표준편차 : s : √s² : 분산의 제곱근
어때? 보기 참 쉽지? 그럼 이제 스프레드시트를 활용해서 이것들을 구해볼까?
전에 범위 설명할 때 예로 들었던 평균은 같지만 변산성이 다른 C집단과 D집단을 가지고 예를 들어 볼게.
C집단 X1 X2 X3 X4 X5 10 20 50 80 90 D집단 X1 X2 X3 X4 X5 10 40 50 60 90 위 표에서 처럼 C집단과 D집단은 평균과 범위가 같지만 변산성이 달라. 분산과 표준편차를 구해보면서 어떻게 다른지 볼까?
먼저 C집단 부터 직접 계산을 해 볼게.
C집단 Xi m Xi-m (Xi-m)² 10 50 -40 1600 20 50 -30 900 50 50 0 0 80 50 30 900 90 50 40 1600 ∑Xi = 250 ∑Xi-m = 0 ∑(Xi-m)² = SS = 5000 N = 5 ∑Xi / N = m = 50 s² = SS / (N-1) = 5000 / 49 ≒ 102.04 s = √(s²) ≒ √102.04 ≒ 10.10 s² (분산) ≒ 102.04 s (표준편차) ≒ 10.10 C집단의 표준편차는 약 10.10으로 계산된 것을 볼 수 있어. 다음으로는 D집단도 구해볼까? 대신 D집단을 계산할 땐 C집단과 다른 수치들의 색을 빨간색으로 표시할게. 잘 보이라구~
D집단 Xi m Xi-m (Xi-m)² 10 50 -40 1600 40 50 -10 100 50 50 0 0 60 50 10 100 90 50 40 1600 ∑Xi = 250 ∑Xi-m = 0 ∑(Xi-m)² = SS = 3400 N = 5 ∑Xi / N = m = 50 s² = SS / (N-1) = 3400 / 49 ≒ 69.39 s = √(s²) ≒ √69.39 ≒ 8.33 s² (분산) ≒ 69.39 s (표준편차) ≒ 8.33 D집단의 표준편차는 약 8.33으로 계산된 것을 볼 수 있어.
C집단의 표준편차 : 10.10
D집단의 표준편차 : 8.33
C집단과 D집단의 평균과 범위는 같지만 표준편차가 다른 것을 볼 수 있지! 그리고 표준편차는 변산성을 나타내는 지표라고 했지? 표준편차의 값이 큰 놈이 더 많이 퍼져있다는 뜻이야. 점수들이 더 많이 흩어졌다는 뜻이지. 바꿔 말하면 점수들이 평균에서 더 많이 떨어져있다는거야. 우리가 전에 도표로도 확인해 봤듯이 C집단이 D집단보다 더 많이 흩어져있던것을 눈으로 확인할 수 있었는데, 표준편차를 계산하면서 수치화하여 비교할 수 있게 되었어! 야호!
이제 스프레드시트를 활용해서 계산해볼까?
데이터는 우리가 초반에 배웠던 '손흥민 선수의 토트넘에서의 골 기록'으로 할게.
손흥민 선수의 토트넘에서의 골 기록 시즌 점수 기호 점수치 15-16 시즌 X1 8 16-17 시즌 X2 21 17-18 시즌 X3 18 18-19 시즌 X4 20 19-20 시즌 X5 18 20-21 시즌 X6 22 총합 ∑X 107 평균 m 17.83333333 이 점수치들을 가지고 분산과 표준편차를 구해볼거야. 스프레드시트에서는 위의 표를 가지고

이렇게 붙여넣어주면 돼. 점수치는 C3부터 C8까지 입력되도록말야.
이 점수치들을 가지고 분산을 구하려면 분산을 구할 수 있는 VAR 함수를 쓰면 돼. 분산이 variance라고 했지? 앞글자를 따서 함수 이름을 VAR라고 지었어!
VAR 함수는 아래와 같이 사용할 수 있어.
=VAR(범위)
만약 C3부터 C8까지의 범위의 분산을 계산하고자 한다면
=VAR(C3:C8)

위와 같이 입력해 주면 돼. 약 25.77이 출력된 것을 볼 수 있어. 표준편차는? 분산의 제곱근만 구해주면 되지. 분산을 구했으니까 C11셀의 값에 루트를 씌워주거나 아니면 C3부터 C8까지의 범위를 가지고 표준편차를 바로 구할수도 있어.
만약 C11셀에 계산된 분산에 루트를 씌우고 싶다면 1/2을 제곱하는 것과 같이 표현하면 돼.
=C11^(1/2)
'^'기호는 제곱을 뜻하고 (1/2)은 2제곱근을 뜻 해. 1/2 제곱을 한 것과 2제곱근이 같으니 위와 같이 표현할 수 있는거야. 중학교 때 배웠지?
다음으로는 범위를 가지고 바로 표준편차를 구하는 방법에 대해 배워볼거야. 표준편차 또한 분산을 구했던 것 처럼 함수를 사용하면 돼.
표준편차가 standard deviation이라고 했지? 약자를 따서 STDEV라고 표현했어. 수식은
=STDEV(범위)
로 나타낼 수 있어. 만약 C3부터 C8까지의 범위에 대한 표준편차를 구하고자 한다면
=STDEV(C3:C8)
라고 수식 입력창에 입력해 주면 돼. C12셀에 입력해보면
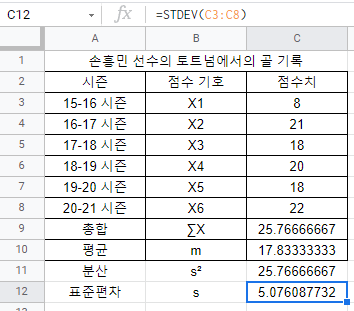
5.07이 출력되는 것을 볼 수 있네! 분산을 구했던 것 처럼 표준편차도 쉽게 구할 수 있지?
위 예제는 https://docs.google.com/spreadsheets/d/1lboVJzWCeOVPO6eUR5ki3SeI0Us62UP071gFdrWeJMM/edit?usp=sharing 에서 볼 수 있어.
단, 분산을 구할 때 N으로 나누는지 N-1로 나누는지는 주의해야 돼. 방금 우리가 스프레드시트를 통해 계산한 것들은 N-1로 나눠서 구한 값들이었어. 모집단이 아니라고 가정했기 때문이지. 만약 모집단의 분산과 표준편차를 계산해야 하는 경우에는 다른 함수를 사용해야 돼. 그 얘긴 뒤에가서 다시 해보도록 할게.
마지막으로 분산과 표준편차에 대해 정리하고 마무리 할까?
1. 평균이 분포의 중심값이기 때문에, 점수들이 떨어진 정도 - 즉 편차 제곱의 합 - 에 근거하여 변산성을 측정하는 것은 논리적으로 옳다.
평균이 다른 그 어떠한 값 보다 편차 제곱들의 합이 적었던 것을 떠올려 봐. 이걸 가지고 분산과 표준편차를 구했으니 당연히 변산성을 측정하는데 논리적으로 옳겠지?
2. 분산과 표준편차의 값은 항상 음수가 아니다.
편차를 가지고 구해낸 값이 분산과 표준편차인데, 편차를 그냥 가져다 쓴게 아니라 제곱했잖아? 음수도 제곱하면 양수가 나오니 절대 음수가 나올 수 없지!
3. 편차가 제곱되면 불균등하게 커지므로, 분산은 평균에서 떨어진 정도에 민감하다.
3을 제곱하면 9가 되지만, 그 세 배 인 9를 제곱하면 81이 되지? 제곱합에 영향이 큰 것이지. 그럼 당연히 평균으로부터 많이 떨어져 있는 점수일수록 민감하게 되겠지!
4. 평균으로부터의 편차의 제곱을 대략적으로 평균한 변량은, 모든 다른 점수로부터 각 점수까지의 편차의 제곱을 평균한 것과 비례한다.
평균으로부터의 편차의 제곱이 그 어떤 다른 수 보다 더 적잖아. 그치? 당연히 이 차이가 커지면 어떤 다른 수에서 각 점수들 까지의 편차의 제곱도 커지겠지.
5. 점수들의 변산성이 증가하면, 통계적 분산도 증가한다.
앞서 우리는 분산을 계산하면서 분산이 크다는 것이 변산성이 크다, 점수들이 더 많이 흩어져있다 라고 배웠어.
6. 만일 점수들 간에 아무런 변산성이 없다면, 즉 모든 점수들이 같다면 변량과 표준편차는 0이다.
당연하겠지? 모든 값이 같은데 무슨 변산성이 있겠어. 모든 값이 평균과 같은데 말야.
7. 어떤 조건에서는 분산이 분할 될 수 있고 그 부분들은 다른 근원에 귀인될 수 있다.
공부를 해서 어떤 시험을 치뤘고, 점수를 받았다고 해 볼게. 그 점수는 어떤 근원에 귀인한 것일까? 지능? 노력? 운? 각각각의 요인들이 분산의 근원이 될 수 있어! 자세한 것은 다음에 알아볼게!
이제 분산과 표준편차에 대해 배워봤으니 다음 시간에는 모집단과 표본집단에서의 분산과 표준편차에 차이에 대해서도 배워볼게! 안녕!
'데이터 분석 > 스프레드시트로 배우는 데이터 분석을 위한 통계학' 카테고리의 다른 글
04-1 척도 (0) 2021.12.07 03-5 모집단과 표본집단 : 모수치와 통계치 (0) 2021.12.02 03-3 변산성의 지표 1 : 분산과 자유도 (0) 2021.11.25 03-2 중심경향의 지표 : 중앙값과 최빈값 (0) 2021.11.23 03-1 중심경향의 지표 : 평균 (0) 2021.11.18